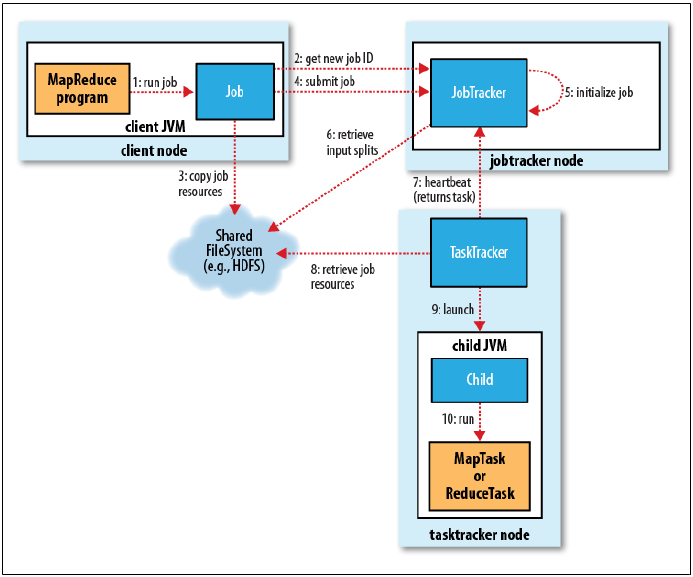
MapReduce Execution in Hadoop
In this article we have tried to summaries, how a MapReduce program executes in Hadoop environment.
MapReduce 1 Execution Sequence:
MapReduce execution starts with below command.
Step 1: $ hadoop jar <jar> [mainClass] args...
This command starts the MapReduce execution in Clients JVM. creates the Job.
Step 2: JobTracker.getNewJobId()
Client Asks JobTracker for a new JobId.
Step 3: JobClient.SubmitJob() / JobClient.runJob()
- Checking the input and output specifications of the job. Computing the InputSplits for the job. Setup the requisite accounting information for the DistributedCache of the job, if necessary.
- Copying the job’s jar and configuration to the JobTracker file-system, in a folder names as the JobId assigned with very high replication factor(default 10).
- Submitting the job to the JobTracker and optionally monitoring it’s status.
- JobTracker puts the job into an internal queue from where JobScheduler will pick it up and Initialize
Step 4: Initialize the Job
- Creates an object of the Job. Encapsulates its Tasks.
- Retrieve the InputSplit and create one map task for each split.
- Creates the reduces task the number of reduce task depends on the number defined in the driver code(default 1).
- Creates a Job Setup task to setup the job before map tasks run.
- Creates a Job Cleanup task to run after the reducer task run.